Rapid evaluation of novel chemistry
by our AI platform
reduces the risk of failure
Heterogeneous data is an asset, not noise
Most scientists and ML practitioners discard subtantial amounts of bioactivity data because absolute values don’t reproduce across assays. We treat that as a modeling problem, not a data problem.
- Learn rank orders, not absolute values — they reproduce across assays
- Use scaffold-agnostic molecular representations — generalize beyond a chemical series
- Result: models that zero-shot generalize to new chemistry
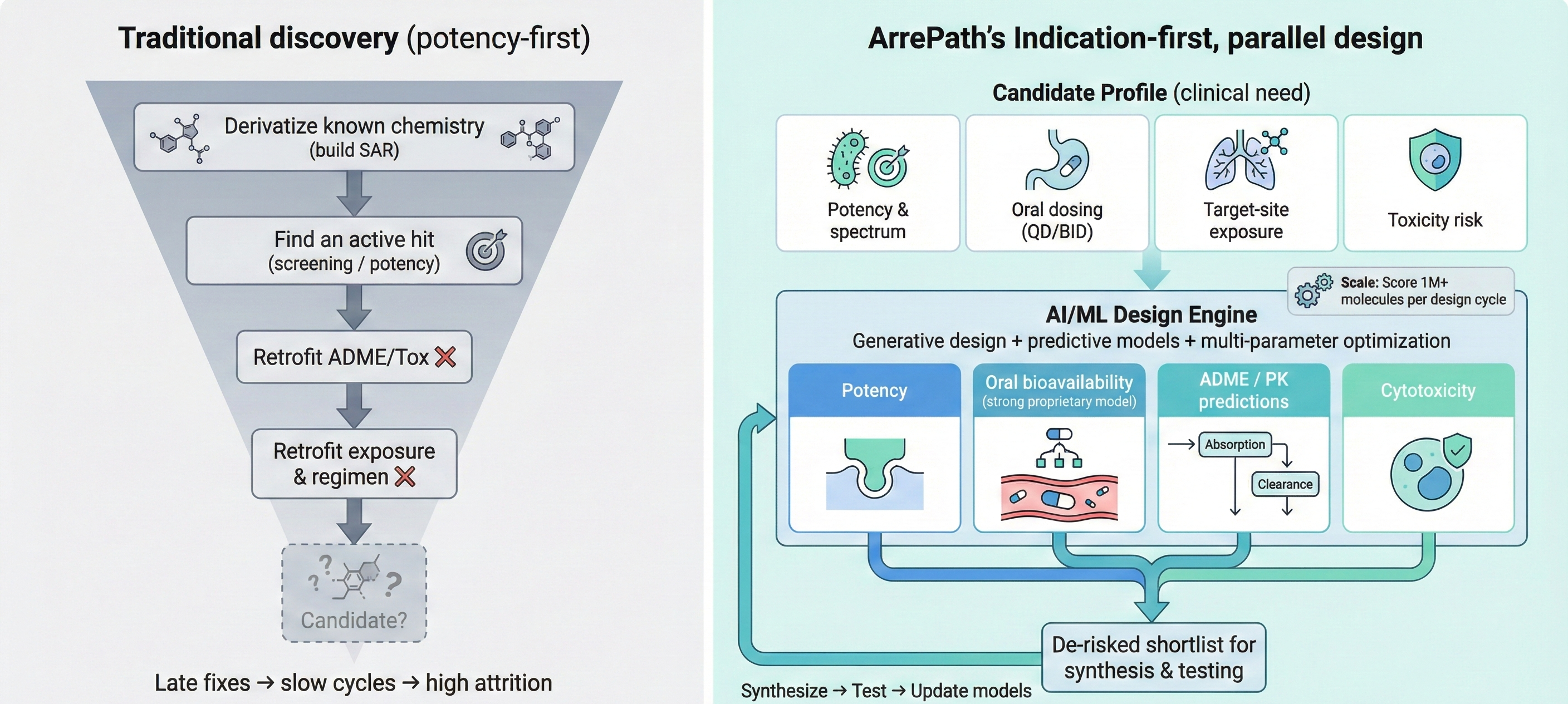
Define the indication first, then design the molecule
Indication-first parallel design beats potency-first sequential discovery
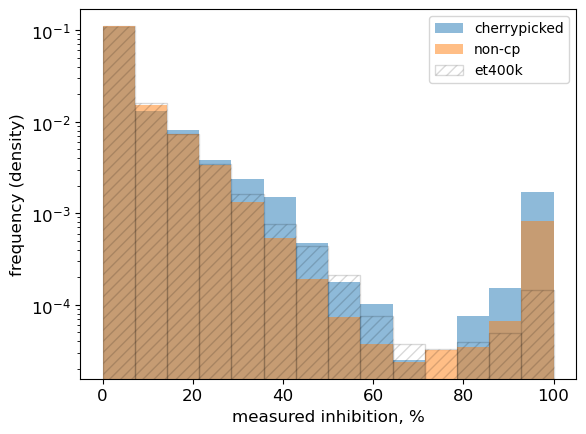
~3× more actionable hits from ML-guided screening
We cherry-picked 5,000 compounds from a 400K library using three predicted properties: high antibacterial activity, low cytotoxicity, and dissimilarity to known antibacterials.
- 2× higher primary hit rate
- 3× fewer cytotoxicity failures
- Net: 3× more compounds worth following up on
This work seeded multiple series for our NTM program.
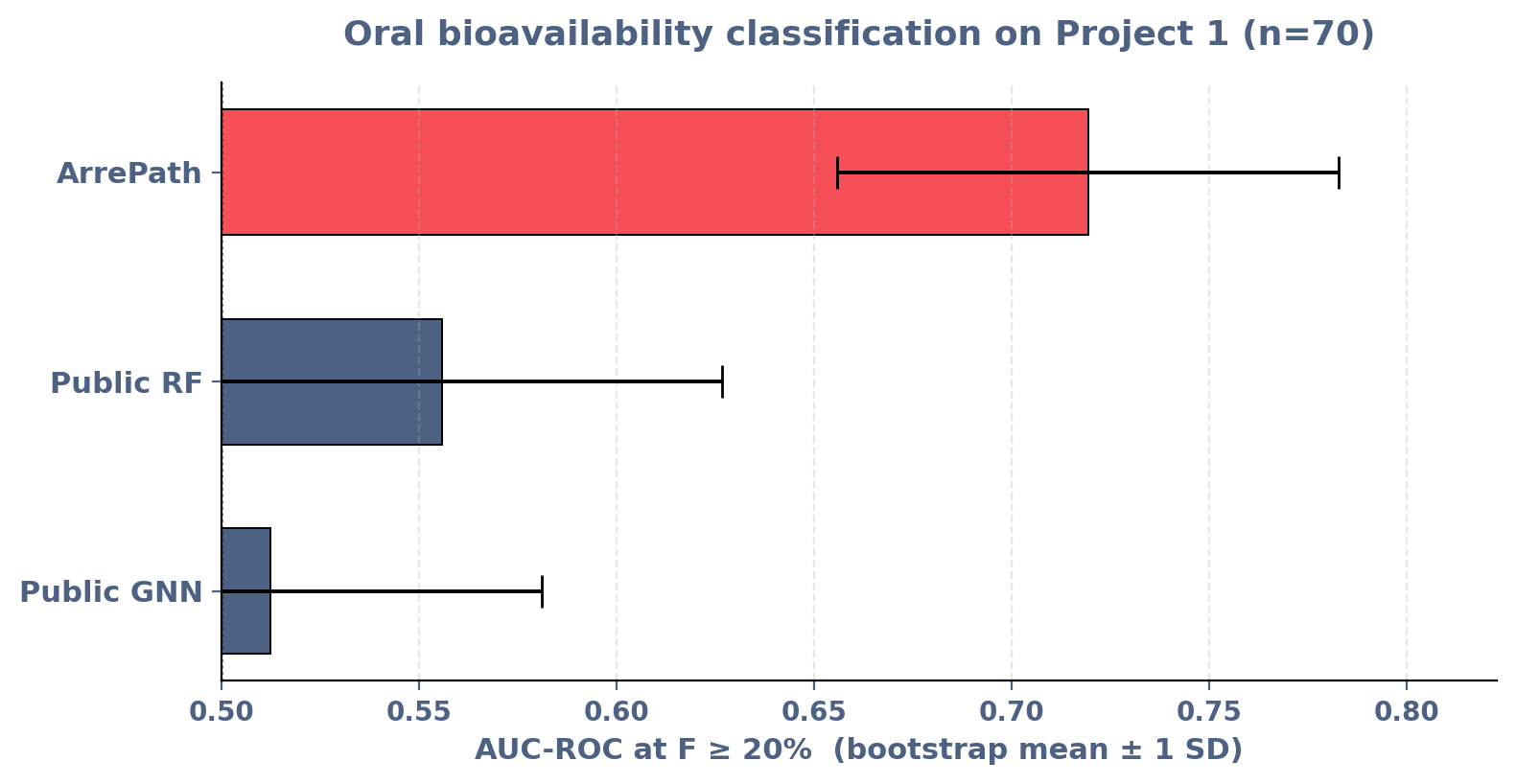
Our models generalize where public models fail
Predict oral bioavailability of our lead-series compounds — our model had no training data on this chemical series.
- ArrePath model: AUC-ROC ≈ 0.72 (zero-shot on the lead series)
- Public Random Forest: ≈ 0.56
- Public GNN: ≈ 0.51 (essentially random)
Cross-scaffold, cross-assay rank-order training is what enables generalization.
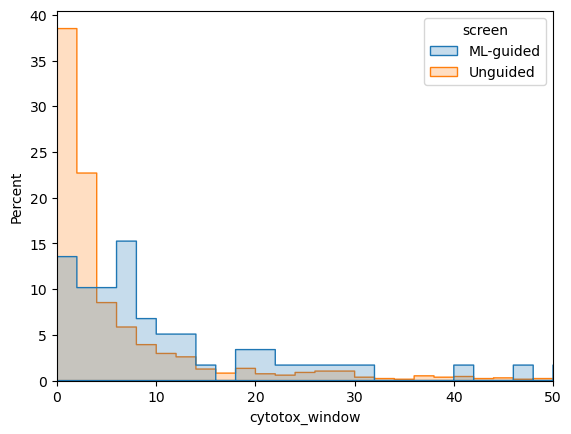
ML-enabled microscopy maps mechanism and flags novelty
Built originally for hit-finding work; remains a complementary capability for any antibacterial program
Mapped antibacterial phenotypic space
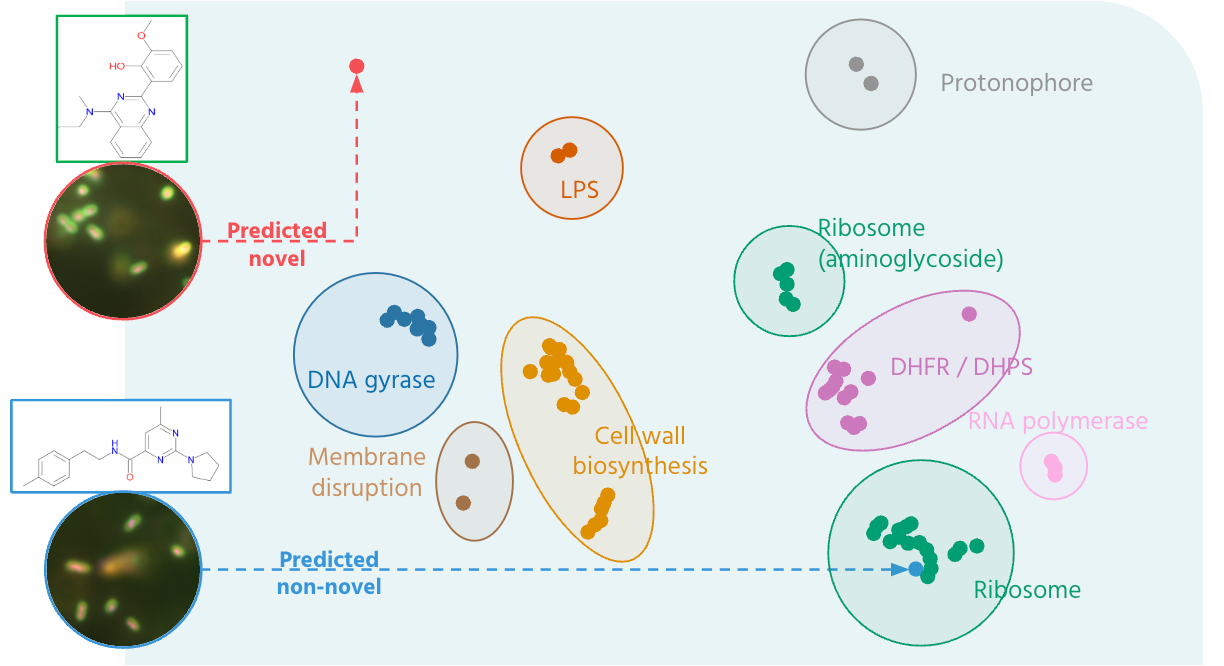
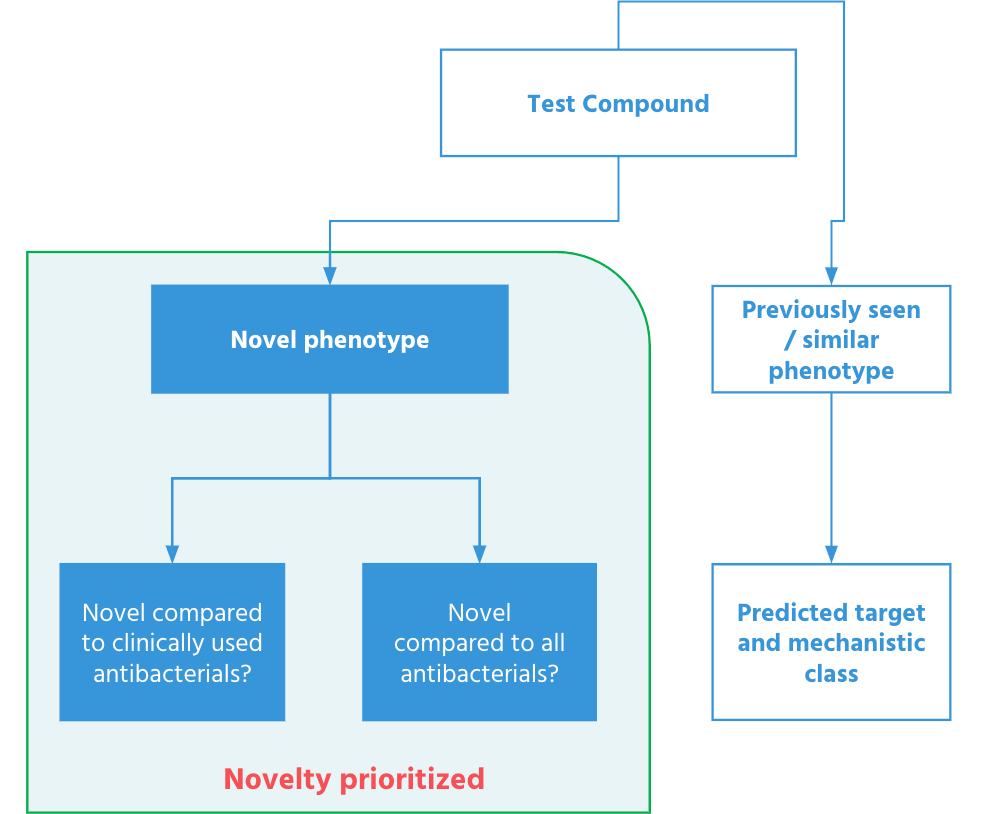
ML models trained on imaging of bacteria treated with known antibacterials predict mechanism of action and flag mechanistically novel compounds. Useful when triaging large hit sets early in a program. Models can be retrained for other therapeutic areas as needed.
See the platform in our pipeline
Project 1 (LpxH inhibitor for outpatient UTI) and Project 2 (NTM lung disease)
Strategy & Pipeline →